In working with a number of file system filter driver projects in recent years we have constructed a model that we refer to as the “isolation” driver – a file system filter (usually a mini-filter) driver that intercepts operations aimed at some set of files and/or directories. The filter changes the content (and potentially the size) of individual files independent of the actual contents of the underlying file. Our goal, in a series of articles, is to describe the basic model, explore development issues and provide a sample mini-filter that implements a model for a data isolation driver. Herein, we first explore common usages, a model, and some high level complications relevant to an isolation driver.
Applications
One model for an isolation filter would be a hierarchical storage manager. Such a component is responsible for moving infrequently used data from online storage to nearline storage devices (traditionally tape, but tape has fallen out of favor in recent years). Another model might be to think of a typical cache system, where one can keep recently used and/or modified data in the cache, while older data is moved to some larger pool of storage.
It turns out that “data isolation” models are actually applicable to a variety of different uses including (but certainly not limited by):
- Encryption filters – they want to show a view of the data that is different than the data contained in the file.
- Compression filters – they want to show a view of the data that is both different in size AND content from the data contained in the underlying file.
- Streaming content delivery – the file starts out zero-filled with data, but information is provided in a “just in time” fashion. For example, some packages might contain huge bodies of information and rather than install all of the data, only the most essential information is installed before the user can begin using the package. The remaining data is then streamed in the background, with priority given to information that is needed by the running application.
- Data deduplication – in this case, the file contents are replaced with some sort of reference to the data, thus allowing duplication to be eliminated or removed.
- Data versioning – in this model, the original file remains, but any changes that have been made to that file are “layered” on top and the filter driver provides the unified (or snapshot-in-time) view of the file.
The key to each of these is that they work best if the filter controls the actual view of the file in order to ensure that memory mappings of the file work properly.
Basic Model
The basic model for an isolation driver is that it controls the cache. This might seem to be more complicated than a “typical” filter. In fact in our experience, any filter that finds itself in the position of trying to manipulate the cache when it is owned by the underlying file system driver becomes much more complicated.
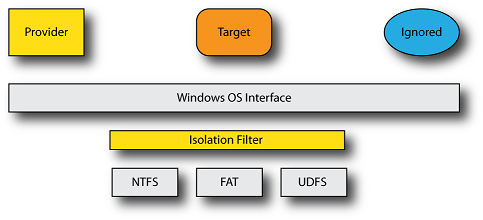
So, our initial and forthcoming sample implementation will start with the simplest of data isolation drivers – one that merely replaces the actual contents of the file with the desired contents of the file. In our model, we consider three different “consumers” for our file (see Figure 1):
- The provider that gives the filter the actual file contents. This could be implemented in the filter itself, although we typically find that some (or all) of this functionality is provided by a user mode service or application of some sort. The isolation filter needs to coordinate access with the provider in such cases to ensure that the provider can access the underlying native file.
- The target that is the application for which we wish to alter the view. This would normally be some “typical” application, for example Word or Acrobat.
- The ignored application for which we do not wish to alter the view. This would normally be some specific application for which we do not want to provide the isolated view. For example, many encryption filters do not decrypt the contents of a file when the application is Windows Explorer.
For our sample, the native file will be the same size as the presented view.
Issues to Consider
Over the years we have seen a number of different filters that try to:
- Flush/purge the underlying file system’s cache.
- Acquire locks (typically via the common header) in hopes that the underlying file system uses that specific locking model (a dangerous assumption, in fact).
- Uses undocumented fields in the underlying file system’s control blocks to determine caching behavior (this is a problem for encryption filters sitting on the network redirector, since the redirector may change caching policy “in flight”).
The model we suggest will work better is to ensure that your filter is not tied to the cache that belongs to the underlying file system driver. We achieve this in the isolation model by:
- Utilizing Shadow File Objects; and
- Providing our own Section Object Pointer (SOP) structure
While this might sound unusual, we observe that using a different SOP structure is how NTFS implements transactions on its files – thus a file has a distinct “view” inside the transaction versus outside the transaction.
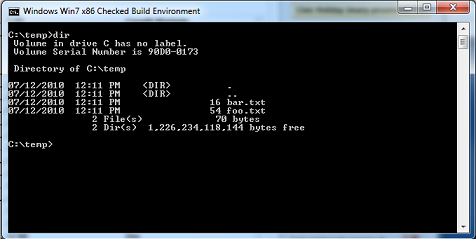
The other complicating factor here is whether or not your filter needs to modify the size of the file. If the file size does not change, you have a simple isolation filter (which is what we’ll build in later parts of this series). The complication is if you need to change the size of the file. Why? Because applications will retrieve those sizes via a directory enumeration operation and not by opening the file and retrieving the size. While it might come as a surprise to some, this really doesn’t work 100% of the time for application programs. In Figure 2 we show what appears to be a pair of files – one of these is 16 bytes long and the other is 54 bytes long. In fact, there really is only one file as we have created a hard link. If we access the file via the hard link, we can see the size change (in Figure 3).
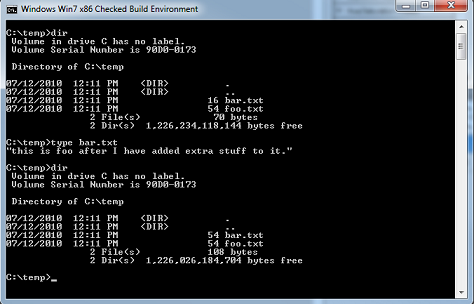
This is because NTFS actually stores the file sizes within the directory entry – but when a file contains hard links, only the link that is actually used is updated. Despite this, applications rely upon correct size information and in some cases they use it for validation.
You can address this by adding “directory size correction” however the overhead for directory size correction can be surprisingly harsh, particularly if it requires opening the file to determine what the correct size should be.
For example, we have found in our own work that adding any additional I/O overhead in directory enumeration can have dramatic performance impact. When this occurs in a high access directory (e.g., “C:\Windows”) the performance of the system can become so poor that your driver will be deemed “unusable” as a result. In such situations we’ve been forced to add caching to the size correction process. Even that will not make the first enumeration of a directory “fast” however. Directory size correction is an area we will leave for a future document and discussion, because it is itself surprisingly complicated.
Summary
In future installments as we build our sample, we will focus on the mechanisms necessary to manage our shadow file objects, contexts and section object pointer structures.
Stay tuned!
