Last reviewed and updated: 10 August 2020
By Alex Ionescu
Community Contributor
One of the signature features of the Windows kernel is the rich array of synchronization mechanisms available for use, most of which are also exposed to 3rd party driver developers. Unfortunately, this is a double-edged sword. On one hand, such a comprehensive set of tools allows developers to choose the best locking mechanism for a particular job. On the other hand, synchronization is a complex topic and the unique properties of each type of lock, combined with sometimes less-than-stellar documentation, leaves many well-intentioned developers confused about which lock is best for a given situation. This can lead to developers choosing a “one-size-fits-all” implementation strategy, where they choose a locking mechanism they understand over more specialized locks that would perform, or fit their needs, better. In the best cases, optimizations are ignored and efficiency is lost. In the worst of cases, incorrect lock usage causes deadlocks or hard-to-diagnose issues as subtle scheduler and IRQL requirements are misunderstood. The goal of this article, therefore, is to examine both changes in how some of the more well-known locking mechanisms work, as well as to describe the latest generation of synchronization primitives. Note that this article doesn’t attempt to go into the deep implementation details of these locks, or cover non-3rd party-accessible locks as the book Windows Internals does. Also not covered are non-lock based synchronization primitives such as InterlockedXxx APIs or other lock-free semantics. You should expect to have to consult MSDN for additional information.
Asking the Right Questions
I often see driver developers asking “what lock should I use?” and expecting some sort of universal answer – instead of thinking of the different lock primitives offered as akin to tools on a belt. Much like you wouldn’t want to sit through LA traffic in a Ferrari, or drive a Prius at Nuremberg, each lock offers its own pros and cons, and picking the right lock is often about understanding its characteristics and how those characteristics map to the lock’s intended use. Once the lock’s primary attributes are understood, it’s often clear what the winning lock is for this particular use. Here’s the first set of questions you should ask yourself each time you attempt to guard against a particular synchronization concern. Note that these are not in any particular order:
- Is it okay to use a wait-based lock, or do I need to use a spin-based lock? Many developers are tempted to only think of IRQL requirements to drive the answer. But performance concerns are also important. Is it really worth taking a potential page fault or context switch when computing a 32-bit hash on 256-byte bounded data?
- Do I need to support recursion in my synchronization logic? That is, should a thread be allowed to re-acquire an already acquired lock?
- Will the data sometimes be concurrently accessed only for read semantics, with only some uses requiring write semantics, or are all concurrent accesses likely to require modification of the data?
- Is heavy contention expected on the lock, or is it likely that only one thread or processor will ever need the lock?
- Does the lock require fairness? In other words, if the lock is contended, does the order in which the lock is granted to waiters matter?
- Are there CPU cache, NUMA latency, or false sharing considerations that will impact performance?
- Is the lock global, or is it highly instantiated/replicated throughout memory? Another way of putting this is: are there storage cost concerns?
Try to build a table that has these questions, and answer each one with a simple “yes”, or “no”.
In some cases, you may need to look beyond just how your code interacts with the data or region of code that needs synchronization, and also analyze the type of machine your code is expected to run on. Also, if the lock is surrounding runtime dynamic data, a consideration might be the amount and structure of the data your code needs to ingest while holding the lock. For example, a Webcam driver is unlikely to be used in a server environment with > 64 processors and multiple NUMA nodes. Webcam I/O is also unlikely to come from multiple threads. Questions around false sharing and fairness are easy to answer in such scenarios.
Types of Locks
Once you’ve gained a clear view of your requirements as described above, your next task is to understand how those requirements map onto the different kernel synchronization primitives. This will guide you to the right lock type for your use. Let’s begin by first breaking down the locks into wait (thread)-based vs. spin-based.
As of Windows 10, the following wait-based locks are available:
- Mutexes, Fast Mutexes, and Guarded Mutexes
- Synchronization Events, and Semaphores
- Executive Resources and Pushlocks
On the spin side, the kernel offers:
- Spinlocks and Interrupt Spinlocks
- Queued Spinlocks (In-Stack and Global)
- Reader/Writer Spinlocks
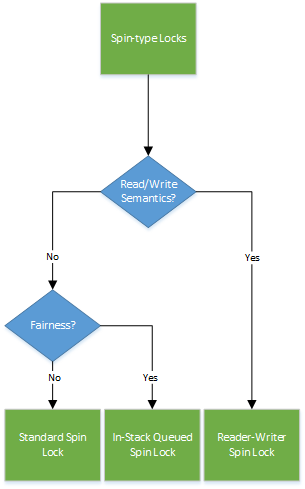
Spin-type Locks
Two things should lead a developer to look at spin-type locks: either there is an IRQL restriction, or the operation that will be performed while holding the lock has a very fast turnaround time: the cost of the potential page fault or context switch that could occur outweighs the cost of keeping the CPU busy during the operation. Things like linked list operations, hash lookups, and maybe even certain types of tree lookups are good candidates here.
If there is an IRQL restriction, is it interrupt based? If so, the exercise ends here: the Interrupt Spinlock is the only kernel-provided primitive that can be used to serialize a code segment with your ISR. Similarly, if interrupts are not involved, there’s no use considering the Interrupt Spin lock as your chosen locking mechanism.
Recursion is our next question, and that is an easy one as well. Simply put, no spin-based lock mechanism offers recursion. In other words, if the requirement is IRQL-based, you must redesign your code to avoid recursion. If the requirement is perf-driven, you need to address what’s more important: the need for recursion, or the need for latency reduction? If recursion is a key need, spin-type locks cannot be used.
Next up is the need to separate reader vs. writer semantics. If all contended accesses modify the data, there’s no need to complicate things with a reader/writer lock. However, if there are performance benefits to be gained because multiple contentions are merely caused by read-only semantics, you may want to use a multi-reader-single-writer spinlock. While not at all well known, Reader/Writer Spin Locks do actually exist. In fact, they’ve been officially available since Windows Vista SP1. An article that describes these locks appeared in the March 2013 issue of The NT Insider.
The consideration that you are likely to encounter next is fairness. If you don’t need read/write semantics, you still have two locks to choose from. On the other hand, if you do, then you need to sacrifice fairness, and Reader/Writer Spin Locks are inherently unfair with regard to writer contention. This makes sense, because if writer contention is a big deal for your use case, the optimization to allow concurrent readers likely won’t help much.
The need for fairness will determine your decision between In-Stack Queued Spinlocks or Standard Spinlocks. As you can probably guess, the former, by adding additional complexity around acquisition, allow an ordered waiter chain to be built, while the latter leave acquisitions to chance.
Spin-type Locks
Note that one of our questions is around the amount of contention that is expected on the lock. It’s important to realize that this question directly impacts the need for fairness: if the lock is almost never contended, fairness does not come into play. In other words, a non-contended use case should just directly utilize the Standard Spinlock, as additional questions basically assume the need to optimize contention.
If fairness is irrelevant, but contention is still an issue, cache line optimizations, NUMA awareness, and false sharing avoidance come into play next, and may offer the In-Stack Queued Spinlock another chance in your implementation. You see, since the Spinlock is a global bit in memory, multiple contenders will spin on the same bit, located in some DIMM on some NUMA node. Immediately, this causes initial memory accesses by other processors to require cross-node memory access, increasing latency. Because each processor is then likely to cache the bit, subsequent spinning on the bit will reduce the non-locality effects, but each modification (due to one processor acquiring the lock) will force a bus-wide cache snoop, adding additional latency. For a highly contended-lock on a NUMA system with a large number of processors, this memory traffic and resulting latency may not be desired.
Finally, if either fairness or locality steered you toward the In-Stack Queued Spinlock, the question of storage costs comes into play. Thankfully, due to the implementation of these locks, both an In-Stack Queued Spinlock and a Regular Spinlock each only consume a pointer-sized slot. At runtime, the In-Stack Queued Spinlock will then consume n-additional instances in memory, but since the lock is spin-based, you cannot have multiple threads on the same CPU in the middle of acquiring different spinlocks – and thus, there’s no storage cost explosion to worry about. We’ll see that this is not necessarily true in wait-based locks.
As we’ve seen, due to the somewhat limited selection of available spin-based lock types, once this direction has been chosen, the choices are somewhat easier to make. Once a key characteristic is selected, there’s usually a single lock that provides the required functionality. The exercise therefore, is deciding what’s more important: latency, fairness, or throughput.
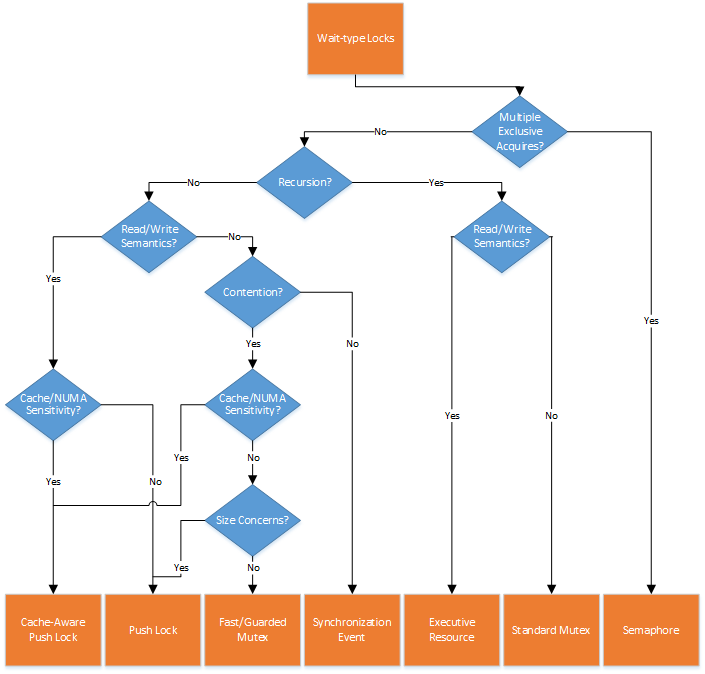
Wait-type Locks
The sheer number of locking mechanisms that utilize the thread scheduler to provide synchronization makes it harder to select a single wait-type lock. However, by understanding some of the implementation details of each lock type, the choice usually becomes just as clear as it is with spin-type locks. Let’s once again follow the previously discussed set of questions to help us pick the correct wait-type primitive for mutual exclusion.
If recursion is a requirement, the choice is immediately limited to two locking primitives: the Regular Mutex and the Executive Resource. If recursion isn’t a requirement, you should probably eliminate these two from the list. Although you can use these lock mechanisms in non-recursive scenarios, they incur an overhead by supporting it.
Next up is the need for single-writer/multi-reader semantics. If you need reader/writer semantics and your locking mechanism also needs to support recursion then your choice is the Executive Resource. On the other hand, if recursion is not needed, then the Pushlock now becomes a candidate as well. Further questions will help you decide between the Executive Resource and Pushlock. Be careful, however! While Executive Resources do support recursion, they support it only within compatible semantic usage levels. For example, an exclusive and shared owner can both attempt another shared acquire – but a shared owned can never attempt an exclusive acquire (it will deadlock on itself). A final remark here is that officially, Pushlock support for 3rd party driver developers is only available starting in Windows 8 and later. Previously, accessing this lock required linking with the File System Mini-Filter Manager and using the FltXxx routines that wrap the Pushlock API, which might look odd for say, a network card driver.
Note that in the wait-based world, there is another type of multiple-acquire primitive that can be used (although one that does not differentiate writers vs. readers): the semaphore. Typically used to protect a group of data resources that a set of threads can use, it functions like a non-recursive Mutex which allows multiple acquisitions from multiple threads – up to a certain defined limit, at which point future acquires will block. If this specific need is part of your requirements, the semaphore is the only primitive which can provide multiple-writer acquisition.
If neither recursion (eliminating the need for a Standard Mutex) nor multi-reader (eliminating the need for Executive Resources or Pushlocks) or multi-writer (eliminating Semaphores) semantics are needed, this leaves the Synchronization Event, the Fast Mutex, and the Guarded Mutex in play. At this point, the choice between the Fast and Guarded Mutex types on Windows 8 and later is an absolute no-op. The two implementations are 100% identical code in modern versions of Windows, contradicting much of the guidance offered in previous books and whitepapers. What gives? Originally, there was indeed a difference. But changes in the hardware of modern processors has over the years allowed Windows to converge the implementation of these two lock types. But we haven’t answered all of our questions yet. Does fairness matter? If it does, it’s important to note that Synchronization Events and Fast/Guarded Mutexes are all fair as they utilize the dispatcher, which implements wait queues. Additionally, Pushlocks are also fair, and even implement wait queue optimization by re-ordering the wait queues. So this doesn’t help us narrow things down.
Let’s look at the contention risks next. In a both highly contended and no-contention scenarios, Synchronization Events will always require a round-trip through the dispatcher, including acquiring the dispatcher lock (with variable costs depending on OS version). On the other hand, Fast/Guarded Mutexes have an interesting optimization: their acquisition state is first stored as a bit outside of the dispatcher’s purview, and only once contention around the bit is detected, does the dispatcher become involved – because Fast/Guarded Mutexes actually integrate a Synchronization Event! This implies that in a non-contended state, the acquisition and release cost of a Fast/Guarded Mutex is as cheap as that of a spinlock, as only a single bit is involved. And so, if your use case calls for a lock that is mostly non-contended, wrapping the Synchronization Event behind the pseudo-spinlock optimization that a Fast/Guarded Mutex offers will prove beneficial and reduce latency.
Let’s look at caching and sharing next. Out of all the locks offered in the wait-based bucket, only Pushlocks offer any sort of NUMA and cache-aware functionality. In fact, a special type of Pushlock, called the cache-aware Pushlock, exists to offer this additional performance gain if needed. Indeed, this does mean that even if multi-reader semantics aren’t needed because all your lock contention is under exclusive semantics, a Pushlock may still be the best solution due to its ability to scale across multiple processor cache lines and NUMA nodes. Unlike a Queued Spinlock, however, this efficiency is implemented at initialization time, and is not a runtime acquisition cost. In other words, using a cache-aware Pushlock in a 640 processor, multi-node machine, can result in multiple memory allocations of multi-KB lock structures.
And this is where the last question comes into play: is this a global lock, or will it be instantiated and replicated across multiple structures? If the lock is going to be replicated multiple times, size must be considered: Pushlocks consume a mere pointer. Executive Resources, on the other hand, consume more than 100 bytes on x64 systems. If recursion is not needed, it’s clear that this cost is not worth it, especially if replicated across multiple structures. Likewise, all Mutex types also utilize 56 bytes, and even Synchronization Events use 24 bytes. If storage costs are important, and recursion is not a need, Pushlocks are great, even if they offer multi-reader functionality you may never need.
If size is an issue and tentatively selected for cache-aware Pushlocks as a result of our discussion above, you now have an unintended side-effect. In order to provide cache-awareness, these types of locks are both padded to cover an entire cache line (64 bytes these days), and potentially replicated across each NUMA node. With a global lock, there is an upper limit on the memory costs of such a cache-aware Pushlock (n CPUs per node * cache line size * nodes), but if this lock is local to a frequently instantiated data structure (let’s say, a per-process state structure your driver maintains), you must now multiply this cost by potentially a few thousand active processes.
With this in mind, Windows 10 includes what is probably the most complex lock yet: the Auto-Expand Cache-Aware Pushlock. As the name suggests, these Pushlocks begin by being cache-unaware: unless there’s significant shared usage, cache and NUMA awareness doesn’t help much, as exclusive acquirers still need to touch the cross-processor local structures, and the storage costs are being wasted. On the other hand, if the usage is agreeable to it, the storage costs may be worth enabling multiple remote processors to hyper efficiently perform read-only operations on the locked data. The Auto-Expand Cache-Aware Pushlock provides the best of both worlds, at the expense of additional internal tracking and telemetry, and a one-time expansion cost.
Ownership
There are a few, minor, one-off considerations that may impact your ability to use a particular kind of lock over another. For example, you may strongly care about ownership. For Executive Resources and all types of Mutexes, the kernel tracks this data for you, and even provides certain capabilities built on top of this semantic: Regular (but not Fast/Guarded) Mutexes can be “abandoned” and provide protection against unexpected owner termination (this should normally only matter for user-mode), while Executive Resources provide lock handoff boosting and I/O boosting to avoid starvation and priority inversion scenarios.
Ownership can also be invaluable for debugging locking bugs in code and deadlock situations, and for locks which don’t provide it (such as Pushlocks or Spinlocks), this can make troubleshooting much harder. You should note, however, that if ownership is important to you merely for troubleshooting, you can easily encapsulate any of the kernel-provided locks in your own data structure, which stores the owner by using KeGetCurrentThread during acquisition, and clears it during release. This also helps you provide assertions against double-releases or recursive acquisitions, which the kernel may only have on checked builds.
APC and I/O Considerations
While the framework described in this article is likely to be sufficient for the selection of the “best lock” for most use cases, it does omit one important detail specific to wait-based locking implementations: the interactions with APC delivery, and ultimately your ability to perform file-system-based I/O, or even certain types of registry access. In some cases, this may prove to be the overriding factor behind the lock selection. We all know that spin-based locks all operate at DISPATCH_LEVEL or above, but wait-type locks are bit more complex.
While the framework laid out above using the series of questions presented appears sufficient for the selection of the “best lock” for a given use case, it does fail to consider one important detail specific to wait-based locking implementations: the interactions with APC delivery, which in some cases may prove to be the overriding factor behind the lock selection. We all know that spin-based locks all operate at DISPATCH_LEVEL or above, but wait-type locks are bit more complex.
In order to actually provide correct synchronization semantics, most locking primitives will disable APC delivery while the lock is held – otherwise, callers run the risk of having an asynchronous routine running and accessing the same data structure that is being locked, and blocking on the same thread. Especially in the case of a non-recursive lock, this would cause a deadlock. In the case of recursive locks, no deadlock would happen, but it is unlikely that such behavior would be desired to begin with. What makes things dicey, however, is that different locking primitives disable different kinds of APCs, and this distinction is often not well described.
For Regular Mutex locks, the kernel will automatically disable normal APC delivery. This means that the code is safe from most types of asynchronous callbacks, as well as being suspended or terminated in the middle of holding the lock. I/O completion callbacks, however, which use special APCs, are not disabled. If such callbacks acquire the same lock as the interrupt thread, however, the recursive ability of Mutexes does protect against deadlock (but developers should still investigate if this is desired behavior).
On the other hand, Fast/Guarded Mutexes disable all APC delivery, including special APCs that are used for I/O completion. This guards against potential unwanted recursion, but it also means that although you can perform file I/O while holding a Regular Mutex, you cannot perform I/O while holding a Fast/Guarded Mutex! Additionally, Synchronization Events do not disable any type of APCs. Therefore, they should almost never be used as true locks, both due to this fact as well as their latency considerations (both of which the Fast/Guarded Mutex takes care of). Keep in mind that writing to the registry does cause underlying disk I/O, so this is yet another operation you must avoid.
This leaves the reader/writer locks – the good news here is that both of them disable APC delivery as well. Because Executive Resources support recursion, this make sense – as long as the I/O completion callback utilizes a compatible use semantic, recursion will not kill the system. Pushlocks, recall, do not support recursion – so you’d expect that just like Fast/Guarded Mutexes, they disable special APC delivery as well. This is not the case – Pushlocks don’t even disable Normal APCs! Because Pushlocks offered so many positive benefits (let’s revisit: small size, cache-awareness, writer/reader semantics, fairness and wait list ordering, all in one!) many pieces of the kernel that perform I/O (including the registry) were eager to move away from the Executive Resource implementation and its large costs and inefficiencies. Since one of the first big users of Pushlocks was the registry implementation in the kernel, it makes sense that the kernel team was willing to sacrifice some safety in exchange for improving key parts of the OS through better locking.
However, due to the inherent risks this poses when used by 3rd party driver developers, who may not be aware of these subtleties, the Filter Manager routines (which are the only way to access the Pushlock functionality before Windows 8) will actually disable APCs for you. But as the Filter Manager is primarily used by file system-related drivers, these routines merely only disable normal APCs. The risk here is that a driver developer who was previously using Fast/Guarded Mutexes to provide mutual exclusion, may now be interested in the benefits that Pushlocks offer. Changing the lock may now subject the driver to unexpected I/O completions while inside of the synchronized region, which at worse, may now attempt recursive lock acquisition. Similarly, a developer moving away from Pushlocks to Fast/Guarded Mutexes, may not realize that this now prohibits performing I/O. Thankfully, there are ways to mitigate both of these risks.
Because APC inhibition can be done in a recursive fashion (i.e.: KeEnterCriticalRegion and KeEnterGuardedRegion are recursive), it’s possible to wrap the call to FltAcquirePushLock with KeEnterGuardedRegion or with a call to KeRaiseIrql(APC_LEVEL), as long as the release path does the opposite. Similarly, because as of Windows 8, the kernel’s Pushlock routines can be called directly (such as ExAcquirePushLock), one can directly decide to call KeEnterGuardedRegion/KeRaiseIrql(APC_LEVEL) to disable all APCs, or even to leave APCs fully enabled. This solves the inflexibility around Pushlocks.
Onto Fast/Guarded Mutexes, the kernel exposes a special set of routines that end in “-unsafe”, such as ExAcquireFastMutexUnsafe. These routines do not inherently disable any kinds of APCs, functioning much like Pushlocks in that logic. This allows the caller to use KeEnterCriticalRegion instead of the normal GuardedRegion/APC_LEVEL change the “safe” APIs use, and implement a Fast/Guarded Mutex that still allows I/O completions. At this point, the onus is on the developer to avoid possible recursion scenarios in such callbacks.
A Final Note on Recursion
Due to their flexibility, and unless latency requirements or other needs prohibit their use, you may have fallen in love with Pushlocks (on the wait-based side) or Reader/Writer Spinlocks (on the spin-based side), but realized that you are unable to use them due to recursive needs which cannot be refactored or redesigned away. It’s important to note, however, that providing recursion support to non-recursive locks is not exactly rocket science. Just like ownership can be encapsulated inside of your own locking data structure, a simple flag (perhaps combined with the ownership data) can then be used to determine if an acquisition is recursive or not. In such cases, incrementing or decrementing a “recursion count” can provide recursion support even for a lock such as a Pushlock, with some additional programming overhead on the driver developer’s part.
Conclusion
The wide breadth of locking primitives in the Windows kernel can sometimes overwhelm developers. Changes to the internal behaviors of certain locks, or the introduction of new locks, can exacerbate this problem, as can hidden assumptions and operations performed by different interfaces to the same underlying primitive. Hopefully, this article provides a comprehensive framework for selecting the right type of lock based on a standardized set of questions, as well as describing deeper considerations that can lead to easy-to-miss design flaws if they are not understood.
Alex Ionescu is a world-class software architect and consultant expert in low-level system software, kernel development, security training, and reverse engineering. He teaches Windows Internals courses to varied organizations around the world and is the coauthor of the last two editions of the Windows Internals series, along with Mark Russinovich and David Solomon. He is currently the Chief Architect at CrowdStrike, Inc and can most easily be reached at @aionescu or his blog at www.alex-ionescu.com.
