In the first part of this series (The Isolation Driver (Part I)), we provided a high level introduction to our model of building an isolation driver. Since that time, we’ve received feedback from a number of people that have found this general model to be applicable to problems they are trying to solve.
In reviewing the original model we provided in Part I, we decided to logically separate out the functionality of the isolation driver into two distinct pieces: the isolation driver and the fulfillment driver.
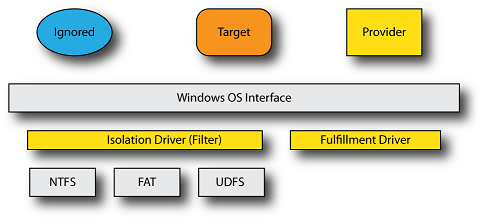
By separating out the functionality into two logical pieces, we allow for the construction of a common isolation driver framework and its combination with a separate fulfillment driver. If your project doesn’t require this sort of separation, you could combine their logical function together – we just decided to split this out because it allows us to build a common (core) isolation filter and allow someone else to construct a fulfillment driver, without requiring they understand the nuances of the isolation process.
Of course, our interest is in examining the issues involved in creating an isolation driver, not in the fulfillment driver (in other words, we don’t really care where the data originates – that’s the job of the fulfillment driver. We just need to handle the presentation of that data to the applications, plus handle the myriad of special cases and situations that might arise.
As it turns out, there are a substantial number of these issues, including:
- Asynchronous I/O
- Supersede, Delete & Truncate Streams
- Byte Range Locks
- Network File Systems
- Mixed 32/64 bit issues
- PNP/Dismount issues
- Filter-filter interactions
- Transactions
We’ll cover these herein, with the balance of coverage for remaining issues to be addressed in Part III (multi-version support, compressed files, re-entrant create calls, reparse points, etc., etc.).
In this and subsequent articles we will cover these topics to further motivate our isolation driver example.
Asynchronous I/O
While most I/O operations are synchronous, for some applications as well as OS level callers, there are cases when the I/O operation can be completed asynchronously. This is an important issue for the isolation driver because it is a hybrid – not a “real” file system driver, but not a traditional filter driver either, as it controls its own cache.
Thus, we need to determine how asynchronous I/O should be implemented. But let’s first start by making clear some of the basic rules of I/O that are true for all drivers in Windows:
- Any IRP can be implemented asynchronously by a driver. This is true even if the IRP_SYNCHRONOUS_API bit is set in the I/O stack location, or the FO_SYNCHRONOUS_IO bit is set in the file object. Corresponding to this is the rule for all other drivers in the system: if you call another driver, you must be prepared to handle asynchronous completion by the driver that you call, regardless of what options you set in the request. Some operations can be “wrapped” and wait (such as IoForwardIrpSynchronously). Be cautious, however, since some operations (directory change notifications and some FSCTL operations, for example) cannot be handled synchronously.
- Any I/O operation can be implemented synchronously by a file system driver. Even if the caller has not requested synchronous behavior, it can be implemented in such a fashion. A filter driver can generally do this as well.
- A driver may determine if the I/O operation is synchronous from the IRP by using IoIsOperationSynchronous. A filter driver may determine if the I/O operation is synchronous from the FLT_CALLBACK_DATA structure, by calling FltIsOperationSynchronously.
With respect to the isolation filter, we decided that the correct choice was to implement our I/O operations synchronously (at least as the general rule) and allow the fulfillment driver to implement asynchronous I/O. This works for us because the fulfillment driver will need to handle asynchronous delivery in any case, such as if data delivery is being satisfied by a user mode service (using an inverted call, model, for example).
Supersede, Delete & Truncate
Subtleties that the isolation filter must handle are the various ways in which something can be deleted. These include the “destructive” create operations, specifically:
FILE_SUPERSEDE – this has the effect of deleting all the streams. Experientially, we have found that a supersede fails if any streams of the file are open, and this is something we need to keep in mind as we construct the isolation filter – depending upon the specific functionality that we require we might be able to defer this decision to the underlying file system. In particular, in pre-Vista systems we do not have per file contexts, and thus we either need to restrict ourselves to Vista (and more recent) systems or we will need to construct our own per file context tracking scheme. In addition, in all cases we should also keep in mind the mapped file cases (and particularly if our provider service and/or fulfillment driver are using streams for some or all of their functionality, which has the potential to complicate things). For our sample code, we will “keep this simple” but for your own isolation project you might need to address this.
FILE_OVERWRITE – this has the effect of truncating the data in the stream, as well as deleting all other streams when the main (default) data stream is overwritten. Unlike the supersede case, from what we have observed, the streams are deleted as they are closed. Again, for our sample, we will simply allow this to be handled by the underlying file system but you may wish to consider handling this in your own isolation driver project.
In addition, we have two ways in which a file can be deleted:
FILE_DELETE_ON_CLOSE – this create option has some interesting properties. First, it is tracked on a per-open instance (for a mini-filter, you can think of this as being “stream handle context” associated state). Thus, it is possible for a file to be opened multiple times, with one of them being FILE_DELETE_ON_CLOSE. When the specific handle is closed, this is converted into a request to “delete the file” and subsequent attempts to open the file will fail with STATUS_DELETE_PENDING.
IRP_MJ_SET_INFORMATION (Disposition) – this is the second way in which a file may be deleted. In this case, the deletion is an intention and can be “undone” until the file itself is closed. Further, there are some interesting issues in cleanup and close processing with respect to files that are delete pending, because they may be memory mapped – and in that case the file deletion cannot be processed until the IRP_MJ_CLOSE (and this might actually occur on a different FILE_OBJECT than the last handle close).
IRP_MJ_SET_INFORMATION (Rename) – this is a subtle case, but one special case of renaming a file is the “replace if exists” option within the rename. For isolation filters these events may need to be tracked and reported to the fulfillment component.
IRP_MJ_SET_INFORMATION (Hard Link) – this is the same case as for rename, just a different (and much rarer) operation. Not all file systems support hard links.
Note that here we’ve discussed “deleting the file.” If anything besides the default data stream is opened in this fashion, only the stream itself will be deleted, not the entire file. Further, there are some subtleties involving streams that we are not fully exploring here.
One important point to understand here: it is not possible, within a filter driver, to know if the file has been deleted. Because deletion is an intention, a lower filter (e.g., an “undelete filter”) can reverse the deletion. This behavior is invisible to anything logically “above” that filter (including our isolation filter).
Byte Range Locks
Byte range locks present an interesting issue for the isolation filter: because the data view to the application is different than the data view to the fulfillment driver (and the provider service) these must be handled by the isolation driver. In other words, do not assume that you can rely upon the underlying file system driver to “properly” implement these.
If your isolation filter need only isolate local file systems, this is not a difficult task to achieve – you can simply use the FsRtl or Flt functions suitable to the task (see FltInitializeFileLock or FsRtlInitializeFileLock for more information.) Using these functions requires:
- Handling lock and unlock calls (both IRP and Fast I/O based)
- Enforcing byte range locks for non-paging I/O read and write operations. It is an error to enforce byte range locks for paging I/O (what this means is that for memory mapped files, byte range locks are advisory, but there is no mechanism for distinguishing user modifications to a mapped file versus write-backs from the cache)
We will discuss the issues for isolation of network file systems separately.
In considering byte range locks, keep in mind that we have two distinct “views” of the file and there is no reason to consider that byte range locking of one should interact with byte range locking of the other.
What does this mean for the isolation driver? If an application locks a region of the isolated view, it should do so against other applications accessing that isolated view. The fulfillment driver and provider service do not need to be aware of these byte range locks at all and, indeed, it is much simpler if we rely upon the byte range lock management of the underlying file system in such cases.
Thus, byte range locks are managed by the isolation driver with respect to the application(s) that are accessing the isolated view of the file (versus the native view of the file). This ensures the provider service will not “run into” byte range locks against the isolated view.
Network File Systems
An isolation filter can, in theory, work with any file system, local or network. For network file systems, however, there are a number of issues that will need to be considered for our isolation filter. For example, there is a fundamental question of “how do we interlock between applications running on different client systems?” There are essentially three ways we can suggest solving this problem:
- Refuse to allow multiple client accesses to the isolation view of the file. This is certainly the simplest implementation but will lead to different application behavior than the native access to the file. For example, Microsoft Word “detects” when a file is already in use by using shared access to that file (and making a copy of the file in case where a conflict is detected.) This is lost if you refuse to allow multiple client accesses.
- Permit multiple client accesses to the isolation view of the file, relying upon the underlying file system to police this behavior. This presents a separate challenge, since we only have one file and we are now attempting to police sharing behavior for two different views of the file (the native and isolated views of the file). Unless two files (or two streams of the same file) are used to arbitrate this access, the combination of these accesses across the two files is unlikely to provide a satisfactory solution.
- Permit multiple client accesses to the isolation view of the file, relying upon the provider service (or perhaps the fulfillment driver) to properly arbitrate this behavior. In essence this becomes an implementation of a (simplified) distributed lock management scheme of some sort.
Beyond file sharing we can then decide how to handle byte range locks: using split ranges (so with a single file on the remote, you would use 0-4EB for isolation view locks, and 4-8EB for native view locks, for example,) or extending the distributed lock management to actually implement range locking for the isolation view (and then simply relying upon the native file system to handle the byte range locks on the native view of the file).
Oplocks are another complication here, because oplocks and byte range locks are frequently incompatible with one another – byte-range locks must be policed on the server, oplocks allow clients to cache data, which obviates the need for them to submit I/O operations back to the server. While it is the SMB redirector that uses oplocks for its caching policy, it does not make oplock state changes visible to filters above the redirector. This will require us to either disable oplocks (by taking out byte range locks, typically,) build an SMB network protocol filter (something we’ve theorized but never done), or end up breaking cache coherency between multiple clients.
For our prototype isolation filter, we will stick with a no-shared-access model, which obviates our concerns here. Those concerns are “real” and may be an issue for your own isolation driver project, in which case you will need to address these concerns beyond what we have done in our sample.
Mixed 32/64-bit Issues
Because we must coexist with 32-bit user applications in a 64-bit world, it is important to keep in mind that our isolation filter must properly handle these cases. The most significant issue here is the problem of structures containing HANDLE values. For a 32-bit application, these will be 32-bit values, while for a 64-bit application these will be a 64-bit value.
NOTE: While we’re discussing this issue, we should note that there is a known API bug: both IoGetRequestorProcessId and FltGetRequestor ProcessId return ULONG values, but process IDs are handles. It’s a minor nit (since so far no system has had enough processes to get a value that overflowed 32 bits) but it does demonstrate how easy it is to mishandle 32-bit/64-bit support in Windows.
The most troublesome of these are the inclusion of handles in the I/O parameter block (IO_PARAMETER_BLOCK or FLT_IO_PARAMETER_BLOCK):
//
// IRP_MJ_SET_INFORMATION
//
struct {
ULONG Length;
FILE_INFORMATION_CLASS POINTER_ALIGNMENT FileInformationClass;
PFILE_OBJECT ParentOfTarget;
union {
struct {
BOOLEAN ReplaceIfExists;
BOOLEAN AdvanceOnly;
};
ULONG ClusterCount;
HANDLE DeleteHandle;
};
PVOID InfoBuffer; //Not in IO_STACK_LOCATION parameters list
} SetFileInformation;
The presence of that HANDLE value within the structure does create some grief for us, since the actual size of this data value will depend upon whether or not this is a 32-bit process on a 64-bit OS. If it is, the HANDLE size of the process is not the same as the HANDLE size of the driver, and it is the driver’s responsibility to accommodate this switch in sizes.
Indeed, there are a number of operations in which a handle is embedded, including:
- IRP_MJ_FILE_SYSTEM_CONTROL – this includes a number of FSCTL operations, including FSCTL_MARK_HANDLE, and FSCTL_MOVE _FILE.
- IRP_MJ_SET_INFORMATION – in addition to the parameters block that we mentioned previously, this also includes FILE_RENAME_INFORMATION, FILE_MOVE_CLUSTER_INFORMATION, and FILE_LINK_INFORMATION.
In such cases the isolation filter (and possibly the fulfillment driver) will need to implement proper logic to accommodate this difference in handle sizes. Our sample isolation filter will demonstrate this point when we get to it in a subsequent copy of this article.
PNP/Dismount Issues
If your isolation filter will deal with removable media or removable devices, you will need to handle mount and dismount issues as well as plug-and-play.
In both cases, the most complicated aspect is not just handling the events themselves, but serializing against those state changes along all other code paths. After all, the basic functionality during a device removal or media removal event is “relatively straight-forward.” We need merely delete our data structures. However, if those same data structures are being used in any other code path, we cannot delete them.
In general, the simplest way to protect against this is to use something akin to an IO_REMOVE_LOCK. However, these are documented as only working if they are within a device extension. So, to protect any other structures we might have, we will need to essentially build our own, likely using either ERESOURCE locks or perhaps FltInitializePushLock (in general, we tend to avoid using push locks because they make debugging deadlocks that involve them vastly more difficult). Thus, any code path that uses one of your data structures that is destroyed down the dismount or device removal paths will need to be protected. You can accomplish this by acquiring the lock (IoAcquireRemoveLock or ExAcquireResourceSharedLite) and releasing the lock (IoReleaseRemoveLock or ExReleaseResourceLite) when you exit the protected path. Then, when you need to tear down the data structure, you need to lock it in the appropriate fashion (see IoReleaseRemoveLockAndWait or use ExAcquireResourceExclusiveLite).
Filter to Filter Interactions
A substantial area of complication for any filter relates to filter-to-filter interactions. It is unrealistic to assume that we can enumerate all the sources of such interactions, or advise on how to avoid all of them. However, there are a number of things that we can do to help minimize them:
- Never assume you can ignore a seldom used feature. We’ve seen filters fail to handle all sorts of specialized conditions (open by file ID, reparse points, hard links, etc.) It is important to think through these cases because they will need to be addressed at some point.
- Always ensure your filter can co-exist with itself. For example, if you need to detect re-entrant calls, make sure you use a detection technique that would be compatible with itself (adding a prefix or suffix to the file name is an excellent example of such a technique that does not “stack” properly. ECPs on the other hand do stack, provided each filter uses its own ECP entry).
- Don’t bypass filters below you. It’s tempting at times but can trigger compatibility issues.
- Ensure you go to Plugfest. This is the best way to test against a number of other filters, meet other developers, not to mention find and fix problems in a “real world” environment.
Keep in mind, no matter how well you build your filter, interaction issues are a reality of life. Functional interference (e.g., data scanning logic filters versus compression/encryption filters) cannot be eliminated and active filters change the behavior of the file system stack, complicating the environment.
Transactions
Few things can be more complicated to get right than transactions (particularly in a complex filter, such as a data isolation filter). The simplest thing to do in an isolation filter is refuse to allow transactional operations on isolated files – this is likely to be a “first stop” for a first generation implementation, but can also lead to specific application failures.
In our experience to date, transactions are only used by installer programs (including Windows Update) and our test programs. Transactions are not yet in mainstream application use; whether they will be or not remains to be seen, but it is logical to expect to see them in specific types of applications in the future.
Thus, it is important to at least consider them in a full-blown isolation filter (we are not going to address this in our sample isolation filter, but it is an issue that may require you address it in a commercial implementation).
Then the question is: how do you support transactions in an isolation filter? In fact, the model that we use within an isolation filter (split views) really is inspired by the model in which transactions are implemented in NTFS – by using separate views of the data (“data isolation”) via the Section Object Pointers structure.
There is quite a bit more to transactions than simply supporting split views, however. If your underlying file system supports transactions, you can defer a large number of operations to the underlying file system (notably, those dealing with the “shape” of the name space, for example). Without such support it is unlikely that you will be able to easily build a transactional rename facility (for example) into an isolation filter without constructing your own persistent resource manager. Note: discussing the creation of a resource manager of any type is beyond the scope of this discussion.
Thus, if you can restrict yourself to data isolation, you can then simply treat the transaction as being a separate “view” of the data (albeit with some model for how you handle rollback and commit, perhaps by using the CLFS support within Windows Server 2003 and more recent).
Summary
I wish I could say we’re done, but then we would be leaving out some really important issues to understand with respect to implementing an isolation driver. We’ll wrap up discussion of these in Part III.
